

We've previously looked at the 7 challenges that data pipelines must solve. Next, let's look into the future. In order to understand where things are going, it's useful to first look at where they've been.
200 years ago, if you wanted to send a message somewhere, you wrote a letter and potentially waited years for a response. 150 years ago, you could accomplish roughly the same thing by telegraph in as little as a day. A few decades later, telephone and radio were able to transmit and receive immediately.
The same happened with visual information 80 years ago thanks to the first commercial television. Next came the rise of PCs in the early 1980’s where data could be readily stored and searched (locally). Then, just 25 years ago, the world wide web emerged, and with it, the need for dynamic, distributed data stores.

What have we learned?
For argument’s sake, let's consider our "message" and "data" to be identical. So what have we learned? With each innovation, the data in our pipelines grew and transformed, in terms of:
- Amount — The sheer amount of data a system (a data pipeline is required to handle within a set timeframe. <br>
- Velocity — The speed at which the data travels through the pipeline, which subsequently affects the speed at which a response can be expected. <br>
- Purpose — The function the data being transmitted serves. Is it the message payload itself? Metadata for use by the transmission mechanism? Formatting? Headers? Instructions for another system? <br>
- Trajectory — The direction(s) the data moves in. Data no longer merely moves from point to point, such as with a telegraph, but often between several different sets of points simultaneously, e.g. a TV broadcast. Or a peer-to-peer network or blockchain. This implies that for every single producer, there are possibly many consumers. <br>
- Format — Data may come as structured, unstructured, plaintext, encrypted, binary, or even embedded within other data. Data can also be commands to subsequent systems in the pipeline. Or any combination thereof.
So, what about now?
With the mobile and smart phone, mobile devices and recently, the world of IoT with connected infrastructure and devices, we're seeing the amount of generated data explode and continue its metamorphosis in form and function.
According to IDC, there were 16.1 zettabytes of data generated in 2016. That's projected to grow to 163 zettabytes in 2025 with users worldwide expected to interact with a data-driven endpoint device every 18 seconds on average.
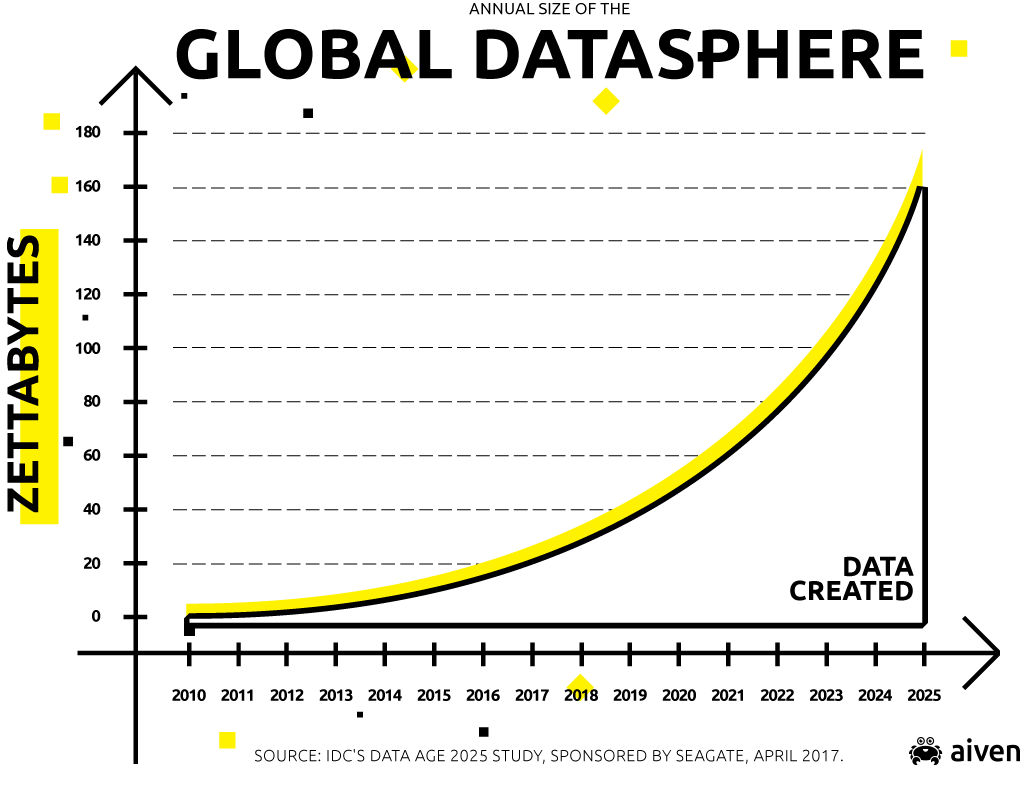
Let’s look at what we believe data pipelines and components will need to be able to achieve in terms of functionality, design, compliance, usability, performance, and scalability to handle this scale.
1. Functionality
Just a decade ago, a pipeline was generally unidirectional, point-to-point, dealt with siloed business background data, and ingested it in batch (often schema-rigid through an inflexible ETL) during off hours when CPU resources and bandwidth were free.
Today, data is ubiquitous and can even be life critical. As such, data is in the foreground of users’ everyday lives. Consequently, pipelines may need to run polydirectionally (from point of ingestion to one or more central data lakes or data warehouses for processing, and back to edge data centers and even endpoint devices to be processed, visualized and rendered).
Much of this happens in real- or near-real-time. Core-to-endpoint analytics, like those found in some modern cars, are a good example of this.
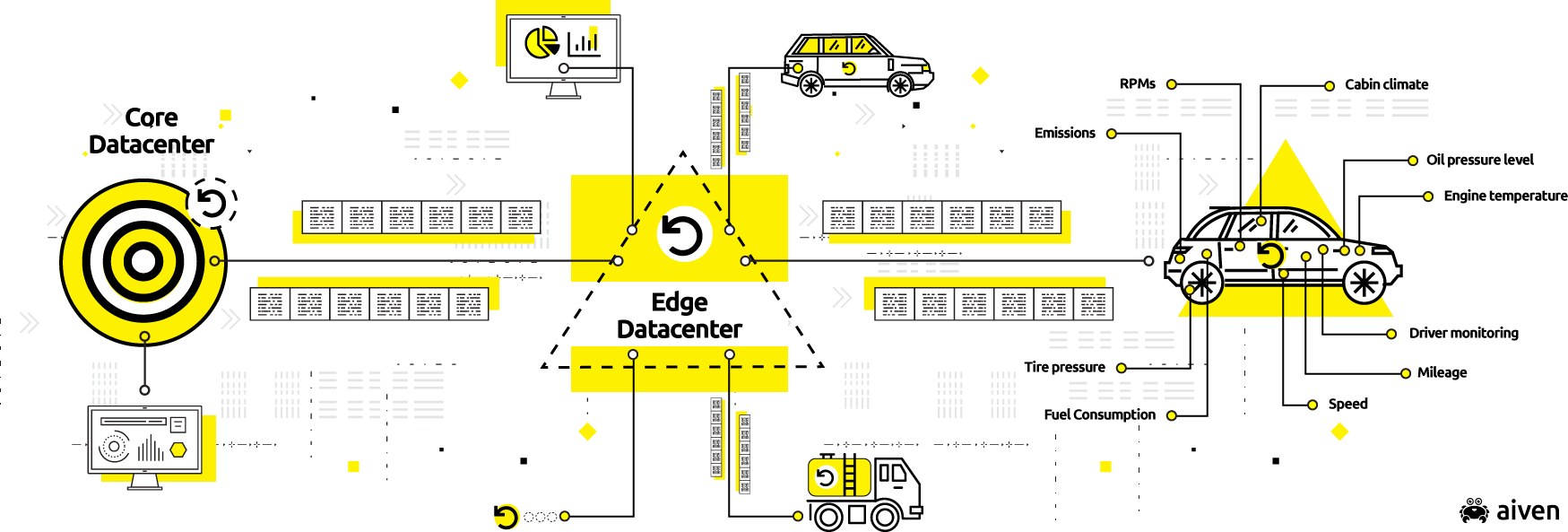
An interesting side-trend emerging from these phenomena is that the data pipelines are not just an IT component supporting the business, but, increasingly are the business.
Alooma is one notable example of a data-pipeline-as-a-service; many other services work in a specific domain with a real-time data pipeline at their core.
As embedded IoT Devices proliferate and mobile real-time data grows, the immense volume of data generated within such pipelines must be accomodated and made appropriately available. This suggests a few requirements:
- Pipelines and their components must be capable of auto-scaling, sharding and partition-tolerance with minimal — if any — human interaction;
- Pipelines and their data flow be troubleshootable and configurable on the fly;
- Pipelines be agnostic to - and able to accommodate — a range of formats, from fully ACID-compliant to completely structured data, but;
- Pipelines implement measures to capture, fix and requeue events that error out.
Analytics pipelines will also increasingly serve as a funnel/conduit for data to be ingested and used toward training AI and ML models. This is already built into systems like Apache HiveMall that sit atop the data pipeline and make deductions, detect anomalies, or translate data into commands for e.g. endpoint devices or connected systems.
These systems will largely self-perpetuate and automate continuous improvements via updates to both the data pipelines and the software components of products.
That said, in the future, the challenge for humans supporting these AI systems won't be as much about training intelligence algorithms or devices (AI will learn to self-train), but keeping an eye on things and, when necessary, intervene to refine/tune/retrain the machine learning component as it self-develops to keep these systems from going off the rails.
2. Design
We've already discussed the need for present and future data pipelines to support core-to-endpoint systems, exponentially-growing data volume and near real-time velocity. But a few other trends are becoming increasingly ubiquitous in the design of data pipelines themselves.
An important consideration for any self-improving pipeline is a kill switch. When the system (or machine learning part of it) begins to go erratic and produce "improvements" that are either suboptimal if not downright dangerous, there must be a way to turn off the pipeline or the machine learning component for troubleshooting or retraining.
Since SQL is such a common paradigm for understanding data, pipelines will continue to evolve to look more like databases: data in the pipeline can be modelled on the fly, and one can query the data in a pipeline at any point — either in motion or at rest — using standard SQL.
We're already seeing streaming SQL variants such as KSQL, SQL on Amazon Kinesis, Apache Calcite, and Apache Pulsar SQL, which are starting to support things like windowing and joins.
While those examples query data in the stream, the next step is to make it possible to query data from anywhere in the pipeline from a single SQL interface. This ties to the notion of table/stream duality that vendors like Confluent are currently talking about.
Another design concern relates to the handling of systems utilizing blockchain or distributed ledgers. Order is important for transactions on the blockchain, while, in many cases, in the presence of a network partition, the compromise between consistency and availability needs to be tweaked.
Similar to how technologies like RadixDLT already do, we'll see more of these systems implementing immutable, ordered, event ledgers as tunably-consistent distributed databases.
In a previous blog, we covered the origin of the publish-subscribe mechanism. It's also important to the trajectory of our data. Rather than having a point-to-point integration between every data producer and consumer (with system complexity equaling n*n), it's far simpler to build data communication around a common interface (complexity equaling n + n) while making our consumers smart enough to decide which data they’ll consume.
As a design consideration then, the pub-sub mechanism will remain a major player in data pipelines; in addition to Apache Kafka and Amazon Kinesis, we'll continue to see disruptors in that space, e.g. Apache Pulsar.
The design consideration underlying all of these points is the immutable, ordered event log. Simply put, producers append to the log in transactional order, while smart consumers select which events they consume.
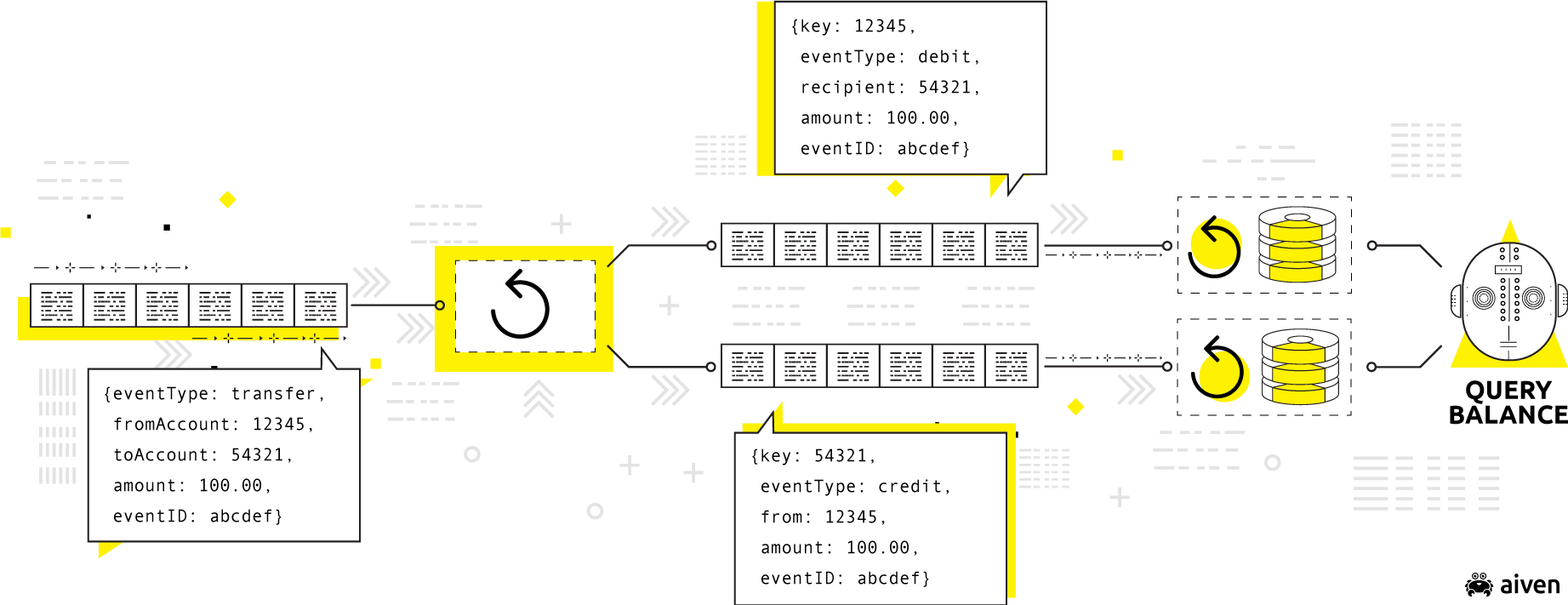
Source: Martin Kleppmann's Kafka Summit 2018 Presentation, Is Kafka a Database?
The immutable, ordered event log is a feature in most data pipelines today, and it isn’t going anywhere.
3. Compliance (including security)
So how will you secure the data in such an event log? As it turns out, more complicated than simply securing the entire log.
GDPR compliance rules are complex, but generally stipulate that personal data with an EU citizen's name or ID be kept accurate and up to date, secure, transparent as to its use, and restricted to the minimum to do the job. Most importantly, under the European Right to be Forgotten, users can withdraw consent to store their personal data.
This makes securing a sequential event log a challenge, as different ranges of rows, or partitions in the log, could correspond to different users' data. So what do you do?
One option is to just discard any personally identifying information before writing it to your data store. However, Yair Weinberger of Alooma was asked this very question during a recent talk and suggested three choices a future pipeline designer can make:
-
If the data is difficult to access, it doesn't exist. Here, the idea is to write different partitions of a log to different locations. Once the permission to the data is revoked (or sunsets), remove or deny access to that location.
-
Automatically anonymize. Email addresses and identifying information can be hashed as you go.
-
Selectively revoke the encryption key. Different partitions in your log are encrypted with keys when stored. When the data permission sunsets, destroy the associated key. SpectX, from Estonia, currently offers yet another choice:
-
Don't move data at all! It's possible to query logs and do analysis remotely -- without ever importing the data to your system. (This also provides the additional advantage of not needing to prepare the data before import!)
Thus, you'll be able to choose whether or not to pipe your data into a system you control or query it in place (or do all of the above from a mix of remote and local locations). But there are some possible trade-offs to consider in terms of:
- latency;
- tunnel security;
- data storage (compliance) requirements;
- storage space requirements (and associated costs);
- CPU/GPU power required (and associated costs).
4. Usability (including designability)
Design relates to how data pipelines are designed — including what features and attributes they have — to handle their requirements (and that of their data). Designability has more to do with what features must be available to users to design pipelines.
As they become more common, pipelines will be assembled from building-block type components like time-series databases, distributed ledgers, full text search, key-value stores, and partitioned, distributed streaming platforms. We expect that users will find full, common configurations available preassembled, installable with as little as a single click.
With an abstraction layer built in, there will be less need to code and configure the pipelines, although customization will always possible. This means GUIs are to be available for the entire lifecycle — from installation and configuration — through to deployment and use and, finally end-of-life. These pipelines will autoscale, with the possibility to add functional, modular "building blocks" as needed.
Solutions like Treasure Data, Alooma, Landoop and StreamSets already let users work with various aspects of Apache Kafka and/or data pipelines via a GUI.
5. Performance (including reliability)
As you can probably guess, performance must generally continue to improve as data pipelines become more widespread: latency will approach zero, while mean-time-to-failure will approach forever.
It's hard to find an exact benchmark that applies to all, as each data pipeline is different. But, over time, we predict that the latency of access to data stores and streams will continue to shrink.
The same goes for measuring mean-time-to failure (MTTF), as a reliability metric: over time, pipelines will approach zero failures (while MTTF → ∞). It's an asymptotic relationship, because of course, queries will always take some time and there will always be some failures.
As companies like ScyllaDB have demonstrated, components will move from interpreted or JVM code to natively-coded elements, which will improve speed, latency and throughput across the board.
These improvements will take place under massively growing loads, whether computation is taking place at the core, an edge data center, or endpoint device.
6. Scalability
The quantity of data generated even within a system is likely to outpace the capacity to store it all. This means that DevOps staff of the future will likely need to make decisions about which data is kept volatile and temporary and which is made persistent and stored.
Metadata will continue to offer space savings, and it's likely that the format of metadata will continue to advance so that those savings can be compounded even more. In spite of all of these developments, pipelines and their data stores will need to be able to massively autoscale to accommodate future load and velocity. This includes the ability to modularize and add components (via containers or VMs, which can be toggled on and off as necessary).
Wrapping up
To get to 163 ZB in 2025 (and beyond), pipelines will need to accommodate data that continues to evolve and transform in terms of amount, velocity, purpose, trajectory, and format, to name just a few attributes.
The data pipelines of tomorrow will continue to evolve, just as those of the past have evolved to today. We've looked at some of what what data pipelines and components will need to achieve in terms of functionality, design, compliance, usability, performance, and scalability.
Aiven offers hosted-database and messaging platform solutions that let you easily spin up state-of-the-art data infrastructure configurations with just a few clicks. Change will come, whether you're ready or not. Want future-proof, scalable, and flexible data pipelines so that you don't need to worry? Try out Aiven for free, for 30 days.
