


What do caching and milk have in common? They're both useless when stale. Whether you're a data engineer or you focus more on the application side, a good understanding of data query technique is important when designing your enterprise data architecture. In this lighthearted blog, we tell you a story about an ice-cream shop, make comparisons between how milk is consumed and how data is delivered, and help you digest (pun intended) the choice of data in your architecture.
Note: This blog uses certain analogies to help make the difficult concepts in data engineering slightly easier. The analogies are not meant to be an exact match.
This is a story about an ice-cream shop. The ice cream shop sells three types of ice cream: a soft ice-cream made from fresh milk, a regular frozen ice-cream, and a specialty ice-cream made from Yak milk. The quality of the ice-cream depends on the quality of the milk that is used to make it. Let's learn about the usage of different types of milk for different ice-creams (and also a thing or two along the way about the choice of data).
The need for fresh milk (or fresh data)
Soft ice-cream is the most popular item in our shop. Although the taste of soft ice-cream is great, using fresh milk comes at a premium cost, as we have to go to the dairy every time we need fresh milk.
Similar to fresh milk, you might need fresh data. If you always query the database directly, and never use a cache, you'll be paying a premium in terms of cost and latency.
The database might have some internal caching to help save your query cost. However, an internal database cache is rather generic and is not customizable to your application. In PostgreSQL®, for example, the internal cache buffer size is configured with the shared_buffer configuration. Allocating more memory to the shared_buffer means that there will be less memory available for other compute operations in the machine’s total memory.
The case of powdered milk (or cached data)
Soft ice-cream is our best seller, but people also buy regular frozen ice-creams from the shop because they are more affordable. We can keep the price down because we use powdered milk for making regular frozen ice-cream. Powdered milk is cheaper by itself, but can also be stocked properly, requiring fewer round trips to the dairy.
In our analogy, powdered milk is like cached data, which can save a round trip to the database but might not be the most up-to-date since, like the powdered milk, it has an expiration date. Data from a stale cache is no good for making business decisions. It's a well known fact that cache invalidation is the second hardest problem to solve in computer science (right after naming things).
Even if powdered milk can be stocked, we still need to make a trip now and then to maintain a healthy reserve of it. In the same way, you need to find a good way to update the cache. There are various caching techniques like cache aside, write through, and write behind to prioritize cost, latency or performance. However, there are trade-offs with every choice and there is no silver bullet. Could there be a solution to consume a constant flow of fresh data without needing to rely on caching techniques?
The case of milk pipes (or streaming data)
The ice-cream shop has been getting a ton of new customers and cannot meet the demand for soft ice-cream from fresh milk. It's clear that fresh milk, the main ingredient, is needed; but how to avoid needing to go to the dairy? One way is to keep a large inventory of milk ready. This will incur large cost and run the risk of a lot of unused milk going bad. Another way is to provide a constant supply of fresh milk, for example, having a dairy company run a milk pipe and have it plumbed into the shop. The milk is pressurized for faster delivery, and we will need to process the milk back to its original form before using it to make the delicious soft ice-cream.
This is similar to the choice between batch processing and stream processing. With batch processing, you collect data at a specified time and the data is typically files of large size. Stream processing, on the other hand, expects a continuous flow of smaller amounts of data so that you can do processing of the data in real time.
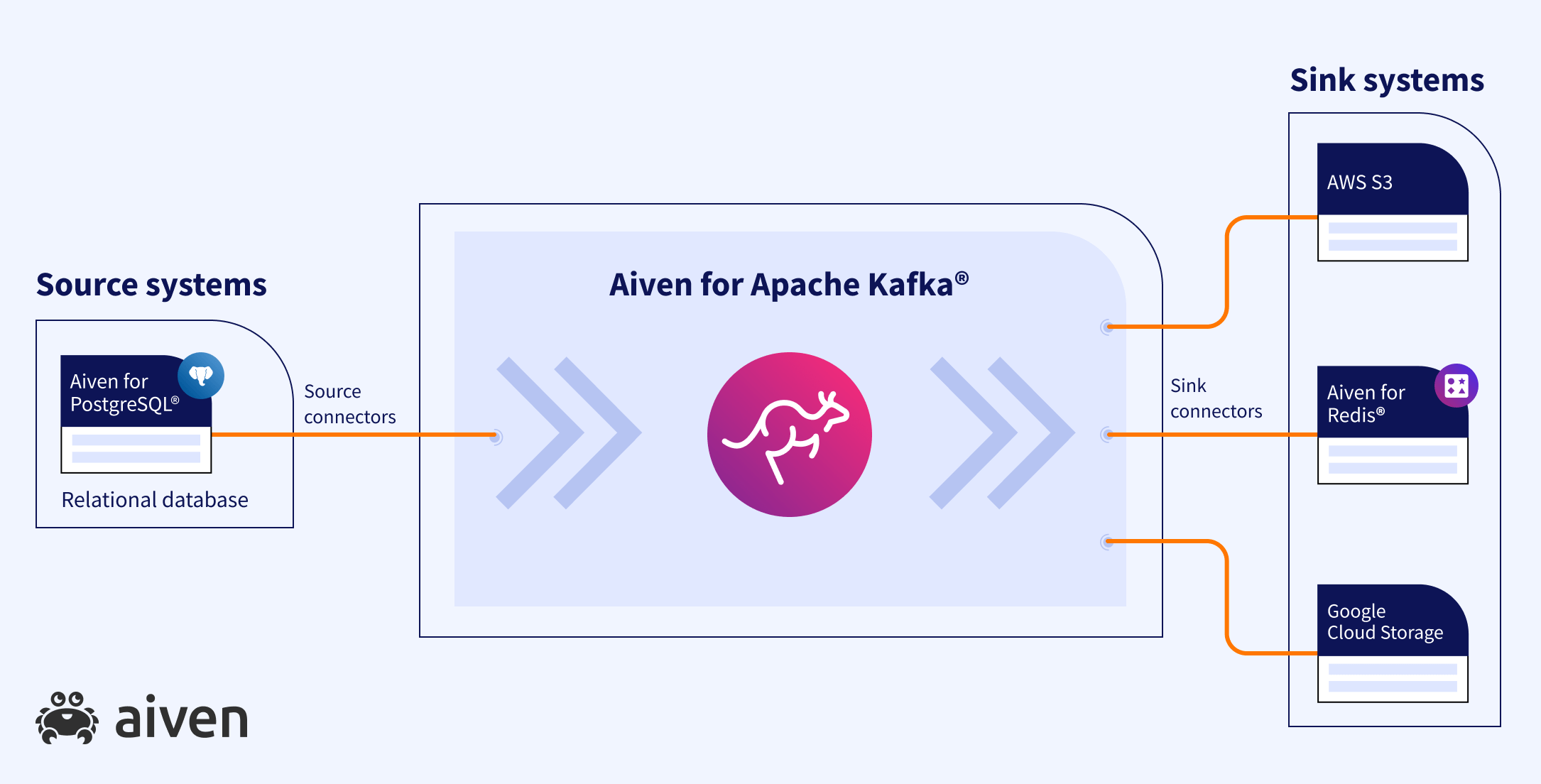
You might have distributed systems in geographically separated regions, with your goal being to move data from a source transaction system to multiple target data stores across the globe. For instance, to move data from a relational database like PostgreSQL® to a key-value store like Redis®*, you can use the Debezium source connector for PostgreSQL to send the data to Apache Kafka® and the Redis sink connector to get the data into Redis. The benefit of this approach is that you can keep on adding more sinks without adding pressure to the source system.
The following diagram shows a sample layout of such decoupled systems with Apache Kafka sitting in the middle.
Freezing the milk (data) for long term storage
If the shop needs long-term storage, freezing the milk is a great choice. It also means we can guarantee to have milk available if there's a high demand during the hot season. Similarly, your archival data could either stay in Kafka for a long time or you can sink to AWS S3 for a more affordable storage option. For example, you might have to archive data for a certain number of years for compliance reasons.
Manage specialty milk (sensitive data)
The ice-cream shop sells a unique ice-cream made from yak milk. We will not find this kind of milk in the dairy and can't afford to store it in the ice-cream shop either. Whenever we need yak milk, we source it locally, taking special care when transporting it, and making sure to use it all up so none is wasted.
Similarly, sensitive data such as API tokens should not be stored in your cache or be streamed in plain-text across the data pipeline. When needed, this kind of data is generated, transmitted as encrypted data, and used. For example, in Apache Kafka, you can apply Single Message Transformations (SMTs) on messages that transform inbound messages after a source connector has produced them, but before they are written to Kafka. Check out an excellent talk on this topic from my colleague Francesco Tisiot. You can also use Apache Flink® to filter or transform sensitive data in real time.
The tradeoff between cost and performance
At the begining, when you have less data and a simple use case, a relational database like PostgreSQL can do the job. It might seem like overkill to worry about caching or a streaming solution. While it's important to keep your architecture simple, it's essential to design for future scaling needs. As the volume of data and the system complexity grows, having multiple systems talking to each other will take a toll on your engineering efforts and cost. You might also need a mechanism in place to transform the data before consuming it. Here are three rules to follow when deciding a tradeoff between cost and performance:
- The actual cost of your software solution includes the current implementation cost and future maintenance and modernization costs. The cost of modification to a mature system is high, and often not possible.
- Open-source solutions will provide you with more control, visibility, and ease of migration over proprietary solutions.
- You cannot expect peak performance from applications that have bottlenecks in the storage and networking layers.
Wrap up
There's no shortage of ice-cream shops and they all have different requirements. If you want your ice-cream (application) to be of the best quality, use quality milk (data) and the right milk storage and delivery (database/streaming) techniques. For a robust and open-source data platform that offers multiple flavors of ice-cream data-related services, give Aiven a try.
