


Pain of Migration
Finding yourself migrating and weighing the options when it comes to moving your entire Apache Kafka® setup to a new cloud? This blog will point you to a solution to efficiently migrate your workloads to an Aiven for Apache Kafka® cluster circumventing the headache that usually comes with cloud migration.
Despite the compelling benefits of transitioning to a more efficient Kafka platform, the migration process itself often presents a significant hurdle. Enterprises frequently encounter challenges such as ensuring data integrity during transit, minimizing downtime for critical applications, and managing the complexities of schema evolution across different environments. The fear of disrupting production systems, the need for extensive testing, and the potential for prolonged migration timelines can deter organizations from making a necessary shift.
Furthermore, reconciling existing client configurations, dealing with diverse data formats, and orchestrating the transfer of large volumes of historical data can add layers of complexity, making what should be a strategic move feel like a daunting technical undertaking.
Solution for the pain
These inherent difficulties are addressed and the solution automated through Aiven’s Migration Accelerator tool. Aiven has designed this to streamline and simplify the transition of existing Kafka clusters to our platform. This purpose-built tool offers a guided approach that walks you through each phase of the migration journey.
During the pre-migration phase, the accelerator assists with comprehensive cluster analysis, identifying potential incompatibilities and providing recommendations for optimal configuration on Aiven. During the migration phase, Aiven for Apache Kafka® MirrorMaker 2 facilitates the seamless transfer of data, topics, and configurations, ensuring data integrity and minimizing downtime. Finally, the post-migration phase offers validation tooling and best practices to ensure a smooth transition and optimal performance on your new Aiven for Kafka cluster. This accelerator transforms a daunting task into an efficient process, enabling organizations to unlock the full potential of a managed Kafka solution.
Steps broken down
To make the migration process simple and replicable, we’ve broken down the entire process into 5 steps. If following along using our GitHub repository, you’ll be able to implement all these steps using our Aiven Provider for Terraform and native Apache Kafka scripts.
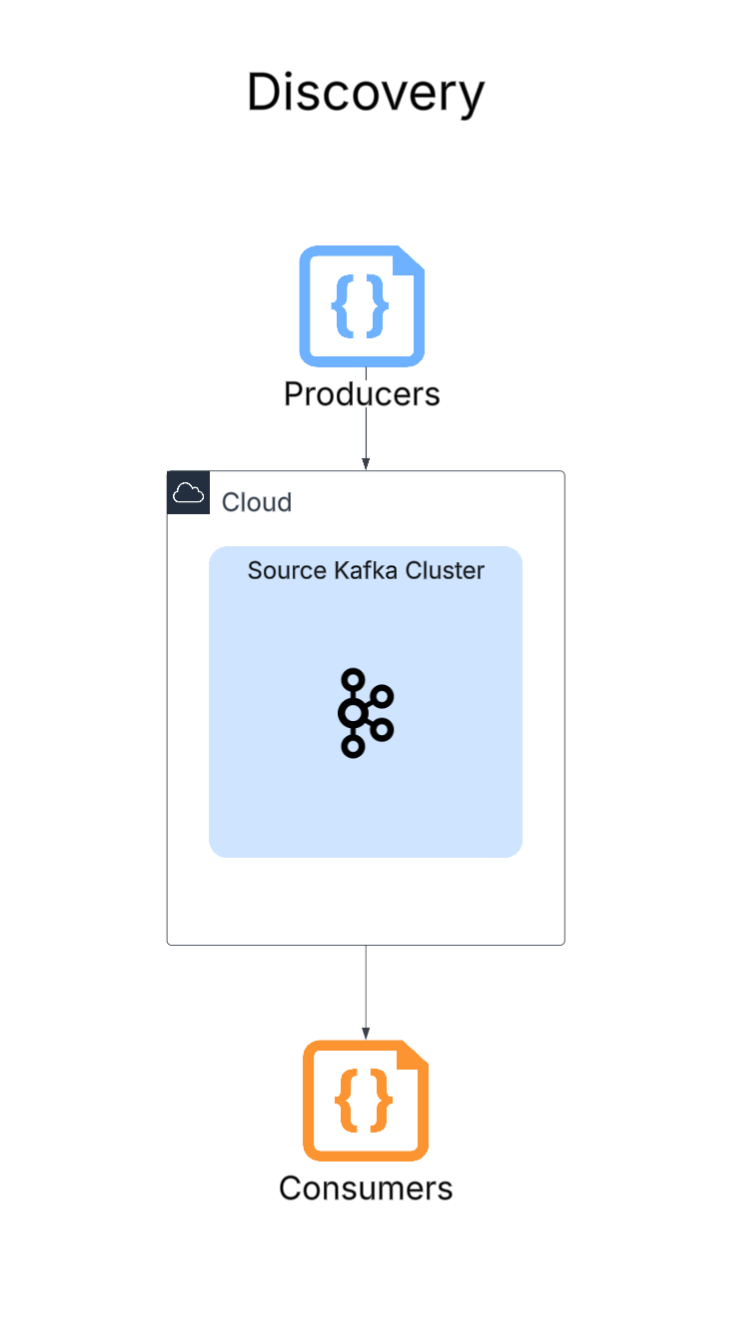
1. Discovery of source system
Plans are how Aiven provides pricing. It's an all-inclusive and transparent way to provide the user with the confidence and ease to forecast monthly expenses without any surprises from variable costs. Due to this plan sizing, it's not always intuitive to know what size of plan you’ll need for your new Kafka cluster.
The first step is to identify not only what your current source Kafka Cluster is running on infrastructure-wise, but also to note how many active topics are on the cluster that you want to migrate, as well as the active consumer groups that should be included in the migration as well. Running the Kafka discovery script allows you to see all this information which leads to correct right-sizing of the new Aiven for Kafka cluster.
2. Aiven Infrastructure setup
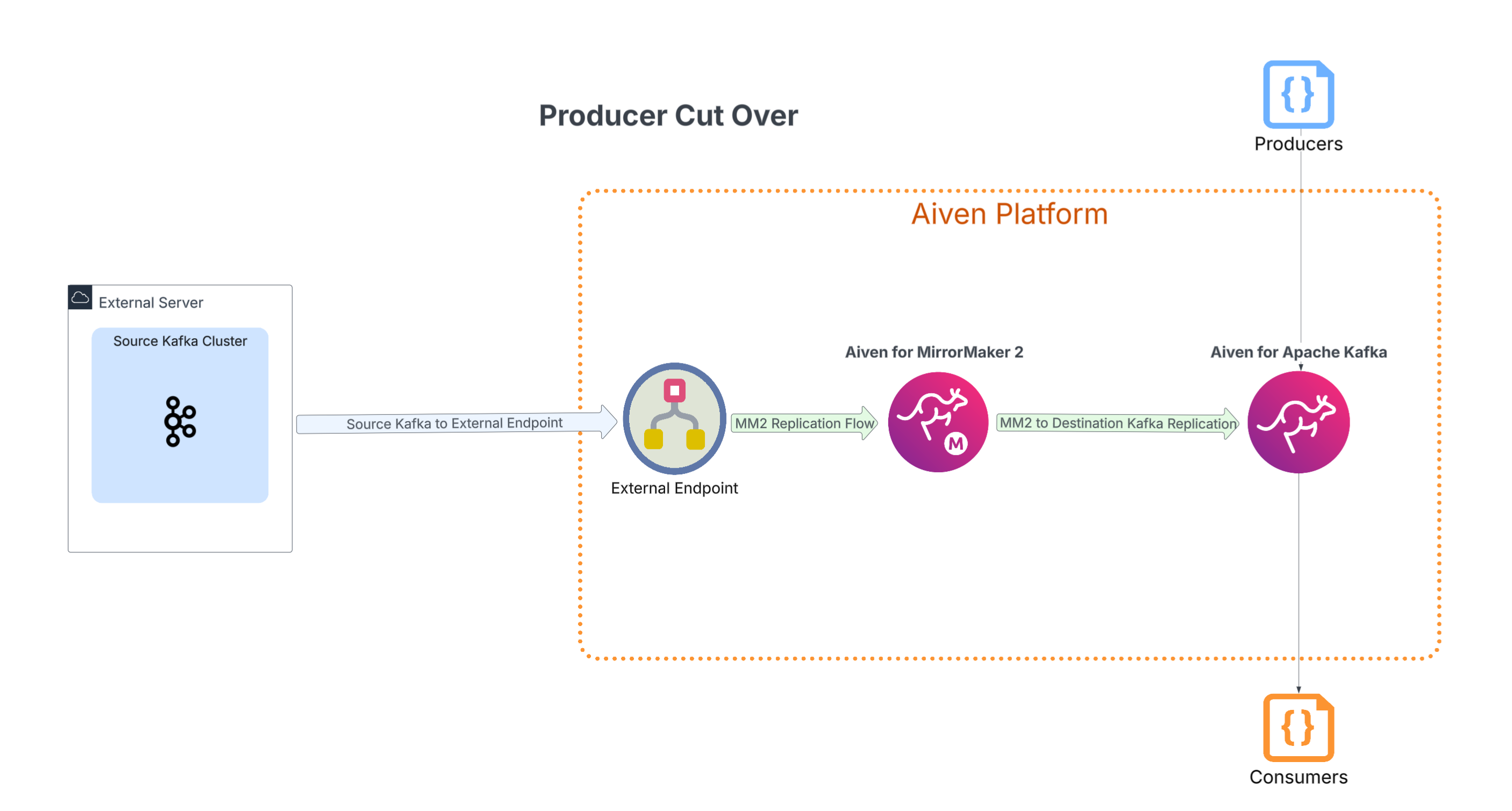
Now that the correct plan size is known for the new Kafka Cluster, we can begin to set up the necessary services for the migration. In this step, we connect securely to the existing Kafka cluster using an external endpoint spun up in your Aiven environment. Once we have that connection point, the new Kafka cluster is spun up on the Aiven platform. With both clusters now established the final infrastructure piece of the puzzle is a MirrorMaker 2 instance.
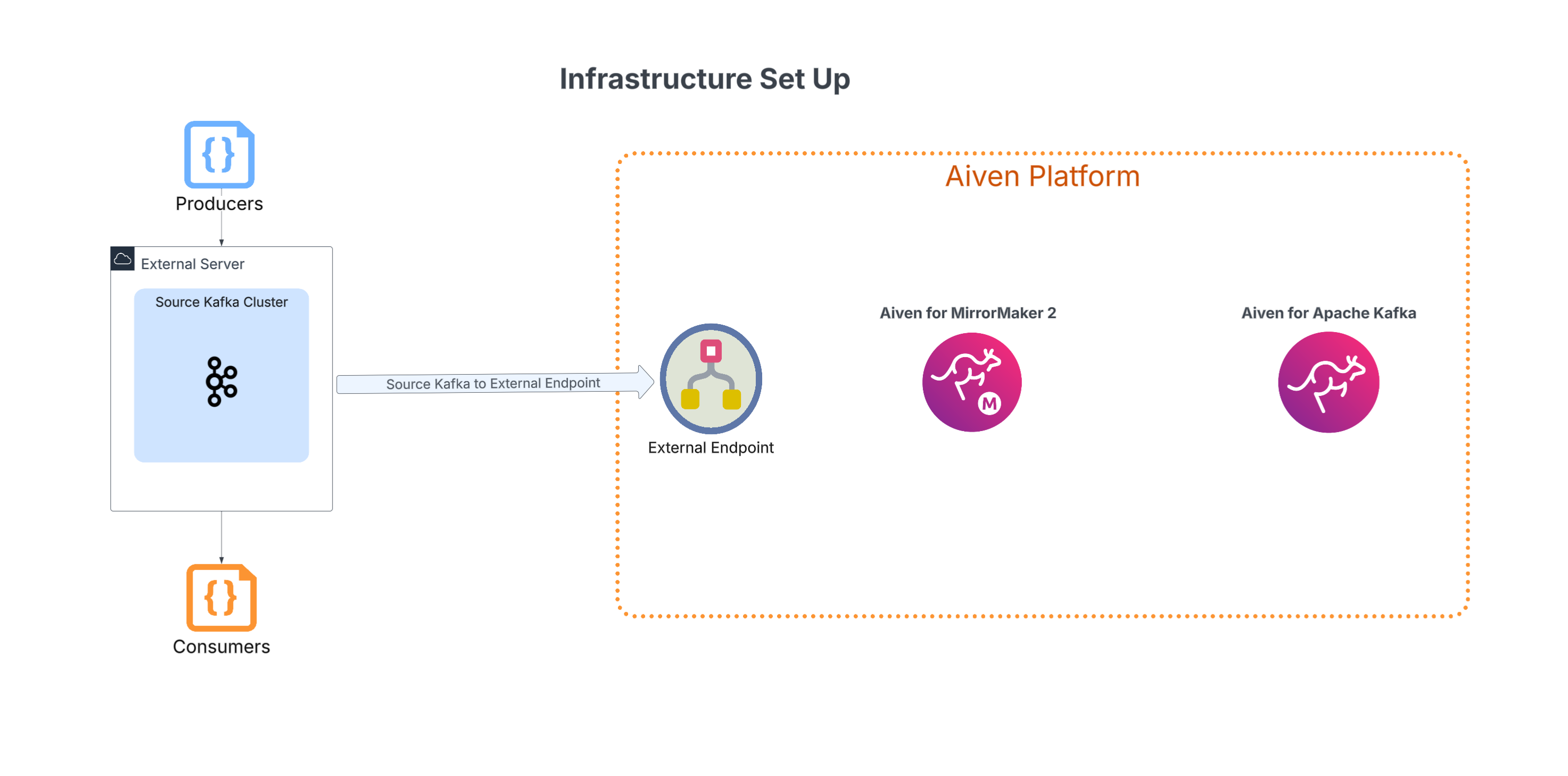
True to its name, the MirrorMaker 2 service will mirror existing topics, configurations, and consumer groups to the new Kafka service. This service is the focal point for this migration process as it begins to mirror your existing cluster onto the new cluster. But hold on, just because the services are created does not mean that the data is migrating already, for that we will need to set up the replication rules in the next step.
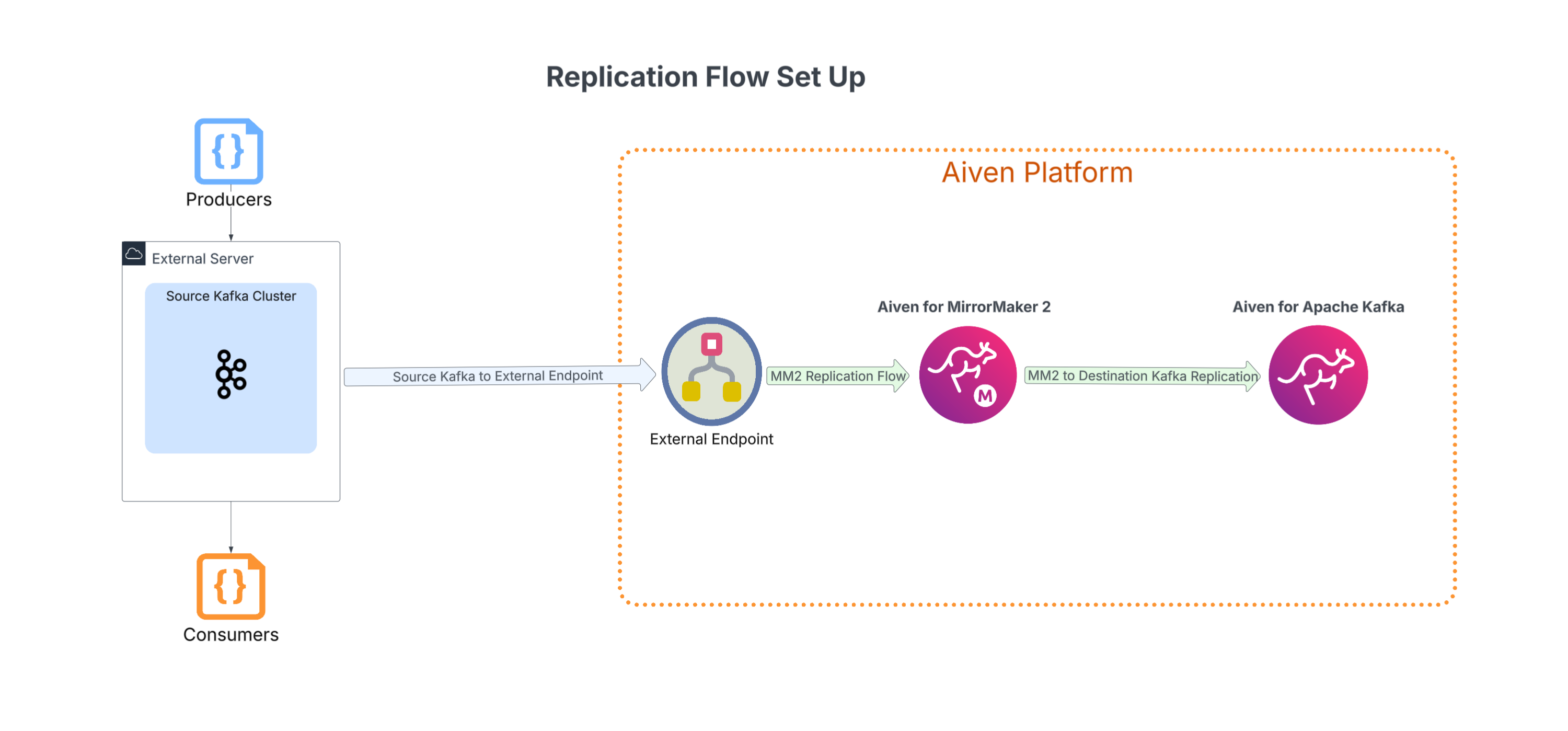
3. Setting up the replication from source to destination
This is the step where we give the MirrorMaker 2 service its instructions so it knows exactly how to copy data. By specifying this data movement from the external endpoint to the new Kafka cluster, the actual migration can begin. The MirrorMaker 2 service will then autonomously and continuously replicate the data, ensuring a perfect copy is maintained on the destination.
4. Spinning up observability of the migration
Observing metrics and logs is essential for a Kafka migration because it provides real-time visibility into the health and integrity of the entire data pipeline. Migrations are complex and high-stakes, with a significant risk of service disruption. Having a robust observability platform allows for continuous monitoring of key metrics such as replication lag, data throughput, and consumer group offset synchronization. By tracking resource utilization and error rates, you can proactively identify bottlenecks and silent failures before they impact applications.
Step four is easily configured using an OpenSearch® database to house logs and Thanos™ to stream metrics. All this data can then be seen on the Grafana® dashboard configured for the migration. Aiven provides all of these services, making integration seamless with our script.
5. Confirming that topics are synchronized on the new kafka cluster
Once we observe that the data is synchronized across clusters, the final stage of the migration is to validate the replication and perform a confident cutover. The priority here is to confirm that all information, especially consumer group offsets, is an exact match between the two clusters. This crucial step ensures that when consumers are transitioned to the new cluster, they will not read duplicate messages or miss any data.
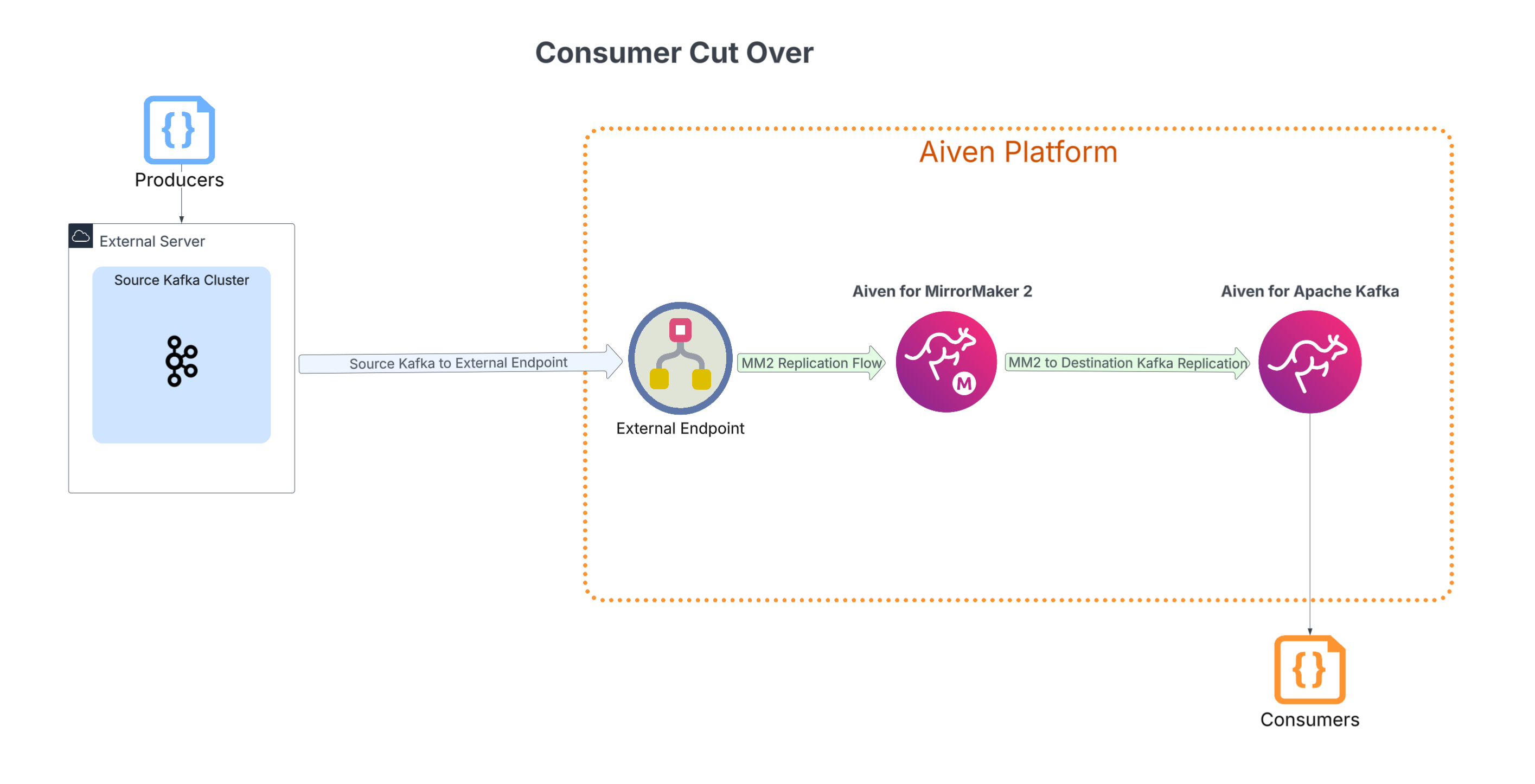
To verify that offsets are correctly synchronized, use Apache Kafka command-line tools. Once this is confirmed, the cutover process can begin. The first step is to redirect your consumer applications to read from the new Kafka cluster. After verifying that they are actively processing data, the final step is to switch your producers to write to the new cluster. A final confirmation that consumers are successfully consuming this newly written data marks the completion of the migration.
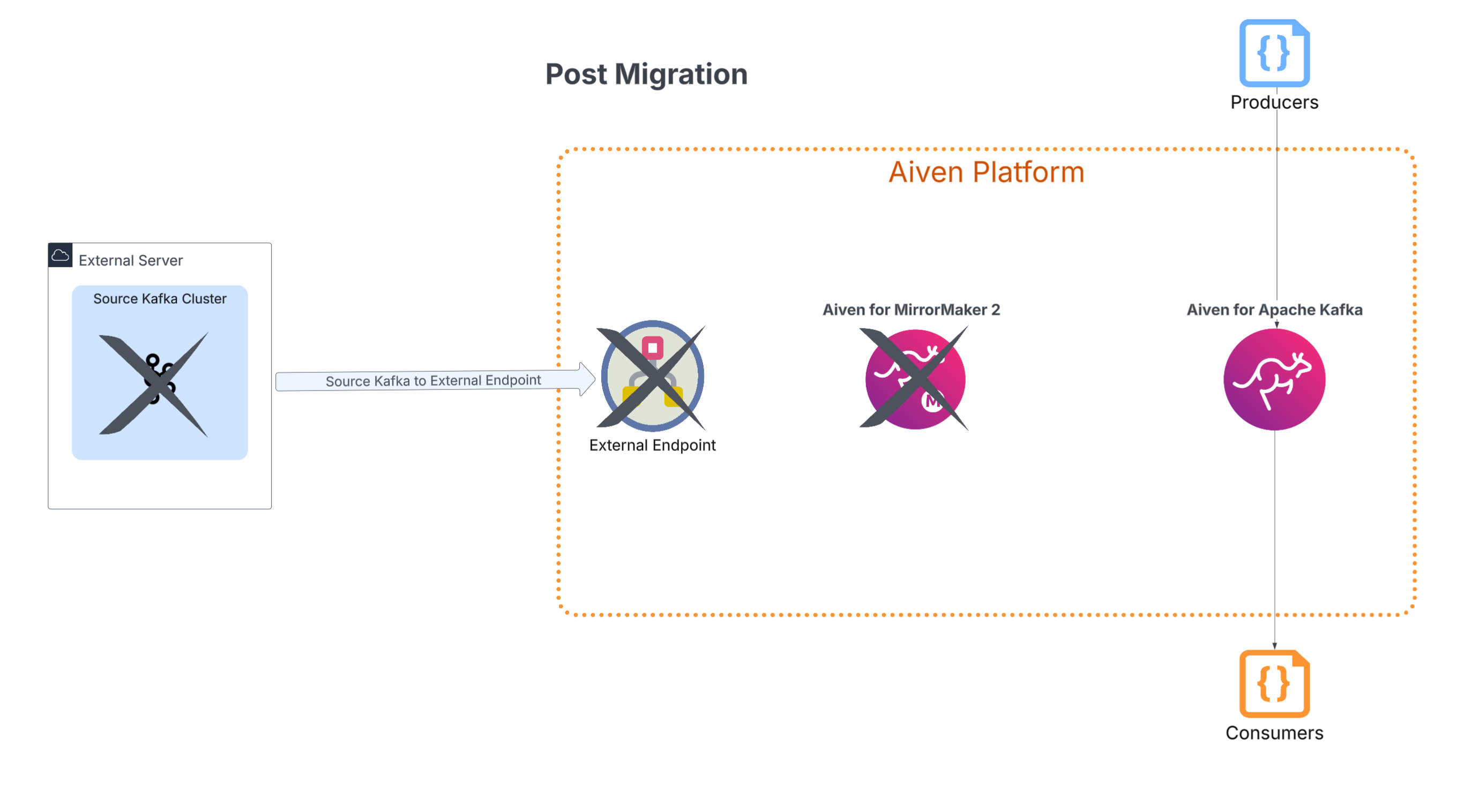
With the migration successfully completed, you can safely decommission the infrastructure used to facilitate it, including the MirrorMaker service. The original Kafka cluster can then be gracefully shut down.
Summary
The Migration Accelerator aims to transform a complex and daunting task into an efficient process, enabling organizations to leverage the full potential of a managed solution of Aiven for Kafka. To see more and use our Accelerator tool, check out our GitHub repo.
To dive deeper into our Kafka offerings, visit the Aiven for Apache Kafka page. You can also get started with a free trial today to experience seamless, managed Kafka for yourself.

Table of contents