


We’ve all built the standard RAG pipeline: chunk data, embed it, store it, retrieve it. It works… maybe.
Just like LLMs have added a thinking mode for better results, we can add a bit of thinking to our RAG pipelines with agentic RAG using PostgreSQL and n8n.
What is agentic RAG?
Traditional RAG is a linear pipeline:
Input → embedding → Vector Search → LLM → Output.
It treats every query identically. Whether you ask "What is our refund policy?" or "How many refunds did we process last week?", standard RAG will blindly search your vector database. In typical LLM fashion, this might lead to a confidently incorrect answer.
Agentic RAG changes the paradigm from a linear pipeline to a loop.
Instead of blindly following steps, an AI agent acts as a reasoning engine. When it receives a query, it pauses to ask: "What information do I need to answer this? And which tool is best suited to get it?"
In this blog post, we’ll use Aiven for PostgreSQL and this n8n template to build an agentic RAG system using n8n for orchestration and Aiven for PostgreSQL for handling chat memory, tools, and vector storage.
Set up n8n
You can set up n8n using docker for free with PostgeSQL or by using n8n cloud.
The "Just Use Postgres" philosophy
Many developers don’t need to save a few milliseconds at the cost of a dramatically more complex system. Instead of using a document database, a relational database and a vector database, you can just use Postgres.
For our system, we’ll use Postgres for three distinct functions usually spread across multiple services:
- Vector Store: Storing embeddings via the
pgvectorextension. - Chat Memory: Persisting conversation history.
- Tools: Creating a direct interface for the LLM to query document metadata and rows via SQL.
This reduces infrastructure bloat and allows us to easily combine data from our agent's memory, our business data, and our semantic vectors.
Set up the database tables
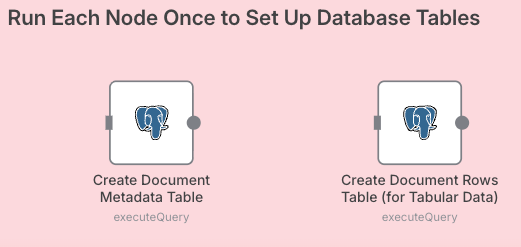
Before the agent can run, the environment must be prepped. In this part of the workflow, we see the two initialization steps
Create Document Metadata Table to store the title, upload time and schema.
Loading code...
Create Document Rows Table to store the actual content.
Loading code...
By running these nodes once, you establish a schema that allows the agent to perform deterministic lookups (SQL) alongside probabilistic lookups (Vector Search).
Separating your data into a metadata table and a document rows table is done to effectively manage large texts. This allows you to query chunked vectors without losing the connection to the source file. Check out our lab, Preparing Data for pgvector and LangChain, to see a more indepth example.
The agentic core
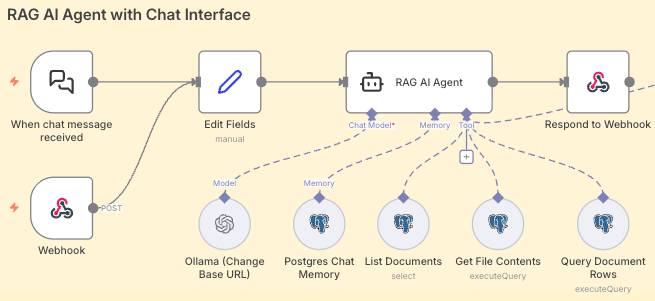
In this section, we have the core workflow logic consisting of the triggers and the RAG AI agent.
The triggers
The flow starts with a chat trigger or webhook, making this deployable as a chatbot or an API backend. The input passes through an edit fields node, which sanitizes the input and structures the JSON payload for the agent.
The RAG AI agent
This is where the thinking and orchestration happen. Unlike a standard chain, this node loops and evaluates the user query and selects the best tool for the job.
We need to plug in three things for the agent to work. The model, such as a local model through Ollama. The memory, where we connect the Postgres Chat Memory node and ask it to create a n8n_chat_histories table. Finally, we have the tools which we’ll cover in more detail next.
The tool belt
Tools are just queries and operations we predefine and make available to the agent node.
We can connect as many tools as we want, but here we only need four tools: three for our documents and one for our vector data.
Document data

This is where "agentic" capabilities shine. The agent is connected to three distinct PostgreSQL tools:
List Documents (Select): A specialized tool allowing the AI to run a SELECT statement on the metadata table.
Loading code...
Get File Contents (Execute Query): Retrieves raw content based on a file_id found in the previous step.
Loading code...
Query Document Rows (Execute Query): Allows for granular row-level lookups.
This is where the agent can write a SQL query to fetch the information that it needs from the documents.
Loading code...
Vector data
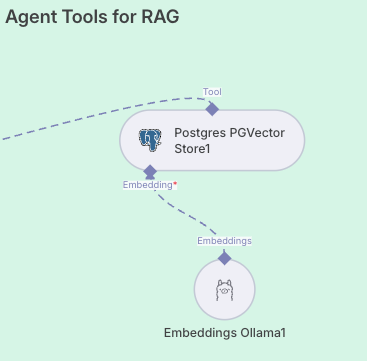
By treating the Vector Store as just one of many tools rather than the only path, the agent becomes smarter. It doesn't waste compute embedding queries that are actually just normal SQL lookups, and it doesn't try to run normal SQL queries on abstract semantic concepts.
Summary
As we’ve seen, unlike linear RAG pipelines, agentic RAG uses a reasoning loop to dynamically select tools to improve retrieval accuracy. By consolidating vector storage, chat memory, and SQL data within Postgres, it simplifies infrastructure while enabling the agent to choose between semantic search and precise database queries.
You can try this out today with Aiven for PostgreSQL and this n8n template. And when your agentic RAG workflow is ready to run 24/7, durable and connected to your tools, take a look at Aiven Managed Agents.
