


Overview
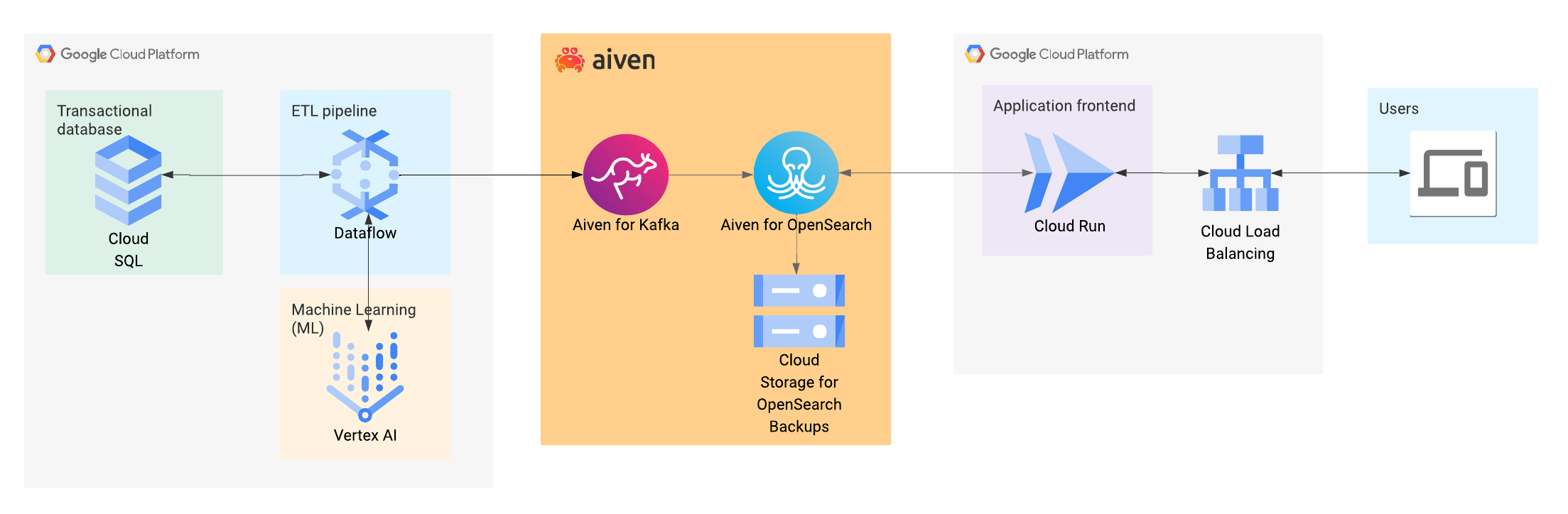
Aiven for OpenSearch® is a fully-managed service that provides an ideal way to run OpenSearch® on Google Cloud. It is designed for companies looking to operate search applications without taking on the burden and complexity of self-managing the infrastructure in the cloud.
Running on Google Cloud, the service is built upon core infrastructure like Google Compute Engine, Google Cloud Storage, and Private Service Connect. This foundation delivers an exceptional performance-cost ratio and supports enterprise-grade security requirements.
To provide a truly Google-native experience for your solution, Aiven also offers native, out-of-the-box integrations with other Google services, including BigQuery, Pub/Sub, and Cloud Logging. It is available through the Google Cloud Marketplace, which allows you to pay for the managed service directly through your Google account.
We're not the only ones who think this is a powerful combination. Companies like Adeo, Mirakl, and Priceline rely on Aiven for OpenSearch® to support their mission-critical search and analytics workloads on Google Cloud.
Aiven for OpenSearch® offers native vector search capabilities to support semantic search applications. Semantic search is different from traditional keyword search in that it considers user intent and meaning to improve the quality of search results.
Semantic search requires converting text, both in the documents being searched and the search query, into vector embeddings, which are numeric representations of words and phrases. Text can be converted into vector embeddings using a variety of models--the embedding model you choose will depend on factors such as performance, output size, cost, and domain-specific bias.
This is where Google Vertex AI comes into play--Vertex AI is a fully-managed, unified AI development platform that simplifies and accelerates the entire ML lifecycle to enable teams to collaborate using a common toolset. One of Vertex AI's capabilities is generating vector embeddings using the latest text embedding model from Google, Gemini Embedding 001, an open model such as E5, or any other supported model deployed in Vertex AI.
In this post, we'll show you how you can use Aiven for OpenSearch® with Vertex AI to build a vector search application.
Tutorial
Pre-requisites
- Clone this Github repo for all the example code and data
- Follow the instructions in this doc with an active Google Cloud account to set up a development environment to use Vertex AI API
- Create a free OpenSearch service on Aiven with these instructions.
Indexing
The dataset we'll use in this tutorial is a small set of 20 sample records representing some products in a sports-related online retail store. These records can be found in the data/sample-products.jsonl file in the associated GitHub repo.
Here's what one of those records looks like:
Loading code...
Instead of indexing these records into OpenSearch® as-is, we'll use Vertex AI to generate a vector representation of the description field values before sending the record to OpenSearch.
Loading code...
For more details, see the Gen AI SDK docs.
In OpenSearch, we need to create an index mapping that expects a field containing a vector embedding, in this case description_vector. The index mapping and settings can be found in data/index-config.json.
In the index setting, we need to set "knn" to true:
Loading code...
More details on the knn_vector type mapping can be found in the OpenSearch documentation.
Querying
When using OpenSearch® for semantic search, you also have to convert the search query text into a vector representation.
Loading code...
Note that when you generate embeddings for the query, you need to specify the RETRIEVAL_QUERY task type instead of the RETRIEVAL_DOCUMENT task type we used when indexing the document earlier. For more details, see the Vertex AI documentation on task types.
Now that we've indexed a few sample records and wrote the code for generating embeddings for the input search query, we can run some search queries. Our expectation should be that even if there is no textual match between the query and documents, using vector representations to perform a knn (nearest neighbor) search should return relevant documents.
The query_opensearch.py script provides an interactive prompt to ask for the search query and executes a knn search.
When we search for "tottenham", the top hits are the "Football Jersey" and "Soccer Ball" products. Even though the term tottenham is not contained in either of those product records, the embedding model provides real world context that understands "tottenham" typically refers to a soccer/football club in North London.
Loading code...
When we search for "lululemon", the top hits are "Yoga Mat" and "Fitness Tracker". Similar to the example above, even though the term "lululemon" doesn't exist in the index, the vector embeddings clearly has the additional context to understand "lululemon" is highly relevant with yoga and fitness.
Loading code...
Conclusion
We've demonstrated how with the power of Aiven for OpenSearch® and Google Vertex AI, we're able to easily build a search application that delivers much more meaningful results than what has traditionally been possible with just keyword search.
Ready to build your own?
Try Aiven for OpenSearch® for free: Start your free trial and see how easy it is to get a vector database up and running.

Table of contents