Manage indices in Aiven for OpenSearch®
OpenSearch® uses indices to organize data into types, similar to databases and tables in relational databases.
In your Aiven for OpenSearch cluster, data is distributed across primary shards, which are replicated to ensure high availability and protect against data loss.
Aiven for OpenSearch does not set additional limits on the number of indices or shards you can use, but OpenSearch itself has a default shard limit of 1024.
When to create new indices
The number of indices directly impacts your service's performance. It is essential to have a clear strategy for creating new indices.
Create a index for each customer, project, or entity if you have a limited number of entities (tens, not hundreds or thousands). Ensure that you can delete all data related to a single entity when necessary.
For example, storing logs or other events to date-specific indices
(for example, logs_2018-07-20, logs_2018-07-21) adds value if you clean up old
indices. If you have low-volume logging and need to retaon indices for longer periods
(years rather than weeks), consider using weekly or monthly indices.
Avoid creating a new index for each customer, project, or entity if:
- You have a very large number of entities (thousands).
- You have hundreds of entities and need multiple different indices for each one.
- You expect a significant increase in the number of entities.
- You don't have a specific need to separate different entities.
Instead of creating indices like items_project_a, use a single items index with a
field for your project identifier. Query the data with OpenSearch filtering. This approach
is more efficient for managing your OpenSearch service.
Setting the number and size of shards
For detailed guidance on choosing the right shard count, see Optimal shards number.
The number of shards you need depends on the amount of data you have. As a general guideline, allocate shard sizes between a few gigabytes and a few tens of gigabytes:
- For a small amount of data but many indices, start with 1 shard and split the index if needed.
- For tens of gigabytes of data, start with 5 shards per index to avoid frequent splits.
- For hundreds of gigabytes of data, divide the total data in gigabytes by ten to estimate the number of shards. For example, use 25 shards for a 250 GB index.
- For terabytes of data, increase the number of shards. For example, for a 1 TB index, start with 50 shards.
These are general guidelines. The optimal values depend on how you use your data and the growth forecast for your OpenSearch data. You can change the number of shards without losing data, but this process can cause downtime when rewriting the index.
Performance impact
A large number of indices or shards can affect the performance of your OpenSearch service. In Aiven for OpenSearch clusters, 50% of the available memory is allocated to the JVM heap. The remaining 50% is reserved for the OS and caching in-memory data structures.
To optimize performance, follow the shard count recommendation of 20 shards or fewer per GB of heap memory.
For example, an Aiven for OpenSearch business-8 cluster with 8 GB RAM should have 80 or fewer shards ().
The shard size also affects recovery time after a failure. Follow the shard size recommendation to set shard sizes between 10 and 50 GB.
Aiven for OpenSearch takes snapshots every hour. If the number of shards exceeds the recommended configuration, the cluster continuously creates new backups and deletes old ones, which can impact service performance by using additional capacity for managing backups.
OpenSearch plan calculator
To help configure your shards, the OpenSearch plan calculator is available for online use or download:
- View on Google Docs - Make a copy to your Google drive to use it.
- Download XLSX - Download and use it locally.
Enter details like the number of nodes, CPUs, RAM, and max shard size to get recommended starting values for your setup.
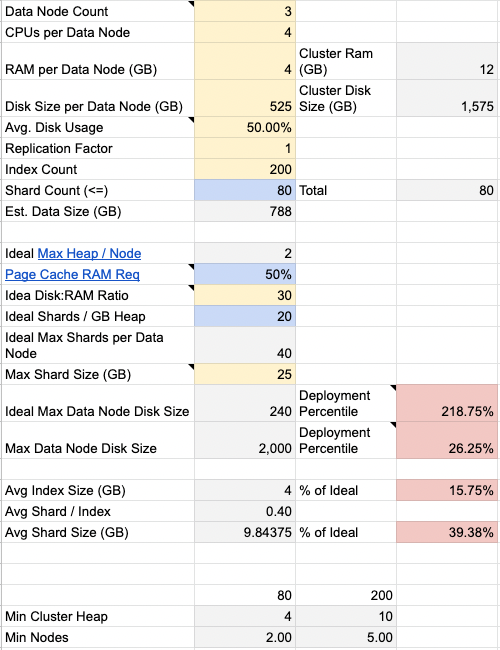
Yellow cells such as data node count, CPUs, RAM, Max Shard Size are input fields
used to calculate recommended plan sizes.
Dashboards from Aiven for OpenSearch are not compatible across minor versions of OpenSearch. If your service instance runs an older OpenSearch version, expect downtime during migration or plan changes.
Set index retention with patterns
The standard approach to index retention is setting a maximum number of indices to store. When that number is exceeded, the oldest index is deleted. However, this approach has limitations. For example, you may need to set different maximums for different types of indices, such as 5 for one type and 8 for another.
Create glob-style patterns
Aiven for OpenSearch allows you to create glob-style patterns to set unique maximums for each pattern. For example:
logs: matcheslogsbut notlogsfooorfoologslogs*: matcheslogsfooandlogs_foo_barbut notfoologs*_logs_*: matchesfoo_logs_barbut notfoologsbarlogs.?: matcheslogs.1but notlogs.11
Use the catch-all pattern
You can also use * as a catch-all pattern to match all indices. This pattern iterates
through all your patterns, so consider the impact carefully before using it.
Example scenario
Consider a scenario where you have the following indices:
- Log indices:
logs.1,logs.2, up tologs.34 - Test indices:
test.1,test.2,test.3, intended for testing but not in active use
If you create:
- A
logs.*pattern with a maximum of 8 indices - A
*pattern with a maximum of 3 indices
Aiven for OpenSearch processes these patterns in sequence:
- Retains the 8 newest log indices according to the
logs.*pattern. - Applies the
*pattern, which affects all indices. The test indices, being the newest, are retained, and the log indices are deleted.
Be careful when using the * pattern, as it might delete indices intend to keep.
Additionally, setting the maximum to 0 disables the pattern. The system ignores the
limit and doesn’t delete any indices. This is useful if to temporarily disable a pattern.
Integration with log retention times
If you use log integration with specific retention times, Aiven for OpenSearch applies both index patterns and integration retention times. To streamline index cleanup, it is recommended to use only one method:
- Set the retention time for log integrations to the maximum value (10000).
- Avoid adding index patterns for prefixes managed by log integrations.
If both methods are used, the smaller retention setting takes precedence.
Related pages
Elasticsearch is a trademark of Elasticsearch B.V., registered in the U.S. and in other countries.