Apache Kafka® upgrade procedure
Aiven for Apache Kafka® provides an automated upgrade process during the following operations:
- Maintenance updates
- Plan changes
- Cloud region migrations
- Manual node replacements by an Aiven operator
Aiven creates new broker nodes to replace the existing ones.
How upgrades work
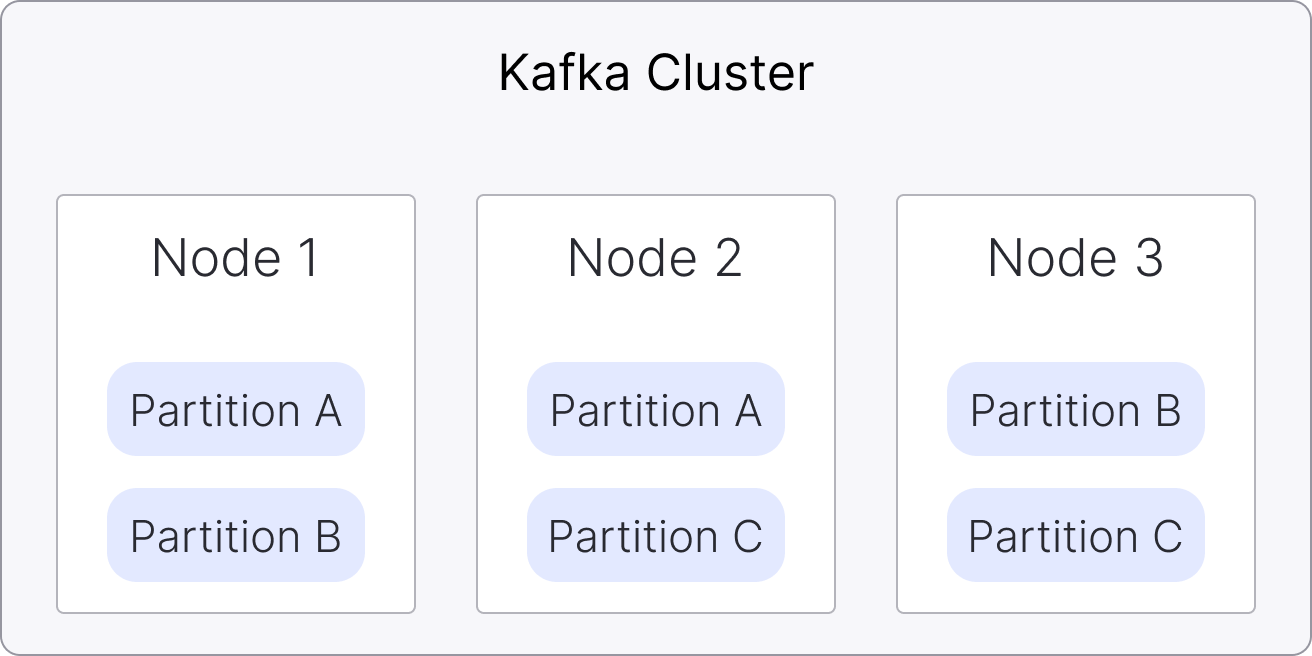
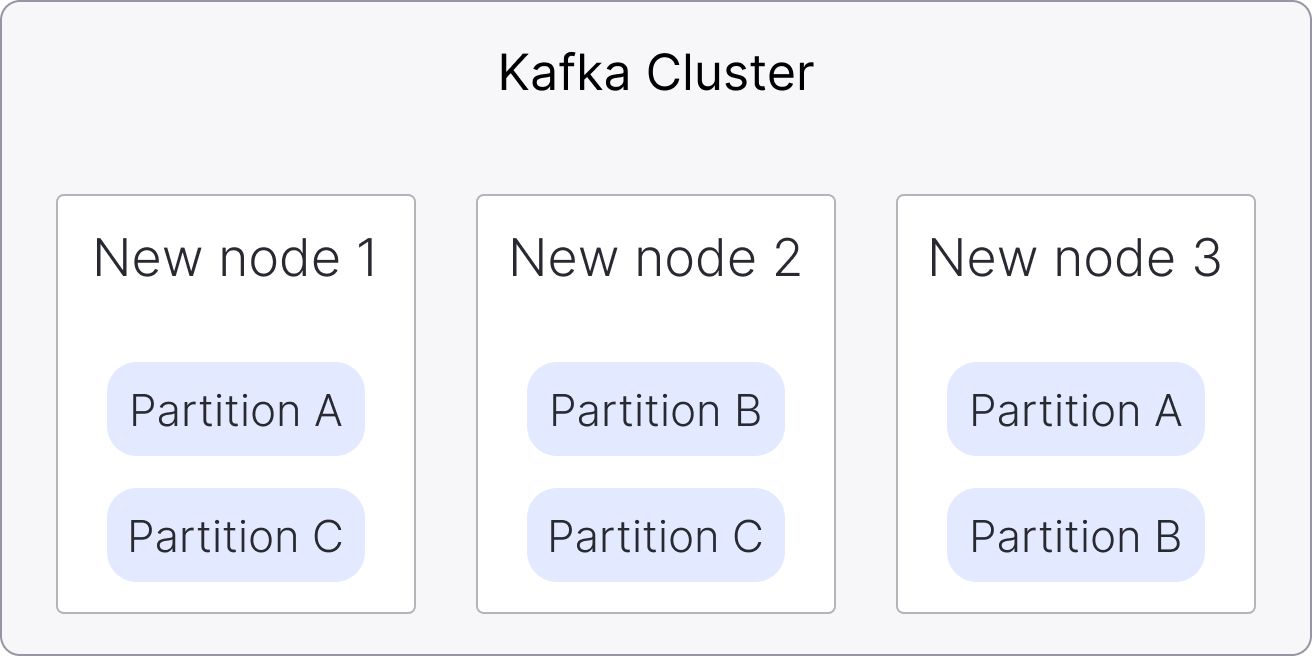
The following steps show the upgrade process for a 3-node Apache Kafka service:
-
Start new nodes: New Apache Kafka® nodes start alongside existing ones.
-
Join the cluster: The new nodes join the Apache Kafka cluster once they are running, and the cluster temporarily contains a mix of old and new nodes.
-
Transfer data and leadership: The partition data and leadership are transferred to new nodes.
 warning
warningThis step is CPU intensive because of the additional data movement.
-
Retire old nodes: Old nodes are removed after their data is transferred.
noteThe number of new nodes added depends on the cluster size. By default, up to 6 nodes are replaced at a time during the upgrade.
-
Finish upgrade: The process completes when all old nodes are removed.
Service availability during upgrades
Your Aiven for Apache Kafka service remains available during upgrades. All active nodes stay operational, and clients can continue to connect.
During upgrades, expect:
- Reduced performance: Data transfers between nodes can temporarily lower cluster performance, especially on heavily loaded clusters.
- Temporary client warnings: You might see
leader not foundwarnings in application logs during partition leadership changes. - Automatic recovery: Most Kafka client libraries retry automatically and handle these warnings without manual action.
These effects are temporary and resolve as the upgrade completes.
For troubleshooting, see NOT_LEADER_FOR_PARTITION errors.
Upgrade duration
Upgrade duration depends on several factors:
- Data volume: Larger datasets take longer to process.
- Number of partitions: Each partition adds processing overhead.
- Cluster load: Heavily loaded clusters have fewer resources available for upgrades.
To reduce upgrade times:
- Schedule upgrades during low-traffic periods.
- Pause non-essential workloads to free up resources.
Rollback options
Rollback (reverting to a previous Kafka version) is not available because old nodes are removed during the upgrade.
Nodes holding data are not removed until data transfer is complete, preventing data loss. If the upgrade does not progress, old nodes remain in the cluster.
If sufficient disk capacity is available, you can downgrade to a smaller plan. Use the Aiven Console or the Aiven CLI to perform the downgrade.
The upgrade process remains the same when changing the node type during a service plan change. For instance, when downgrading to a plan with fewer resources, such as fewer CPUs, memory, or disk space, the latest system software versions are applied to all new nodes, and data is transferred accordingly.
Upgrade impact and risks
Upgrades can increase CPU usage because of partition leadership changes and data transfers to new nodes. To reduce the risk of disruptions:
- Schedule upgrades during low-traffic periods.
- Pause non-essential producers and consumers to minimize cluster load.
If you change to a smaller plan, the disk may reach the maximum allowed limit, which can block the upgrade. Check disk usage before starting the upgrade and make sure there is enough free space.
In critical situations, Aiven's operations team can temporarily add extra storage to the old nodes.
Upgrade to Apache Kafka® 4.0
To upgrade to Apache Kafka® 4.0 or later, your service must first upgrade to Kafka 3.9 and migrate to KRaft mode.
- Services running Apache Kafka 3.8 or earlier (ZooKeeper-based) cannot upgrade directly to 4.0. They must first upgrade to 3.9, which performs the ZooKeeper-to-KRaft migration.
- After migrating to KRaft in 3.9, the service can upgrade to 4.0 or later.
- Once a service migrates to KRaft, rollback to ZooKeeper is not possible.
The message.format.version configuration is deprecated in Kafka 3.x and removed
in Kafka 4.0. Remove this configuration from your topics before upgrading to Kafka 4.0.
Configuration changes in Kafka 4.0
Kafka 4.0 removes and replaces some configuration settings. Update these before starting the upgrade:
-
message.format.version(topic-level): Remove this setting from all topic and service-level configurations. It is deprecated in Kafka 3.x and removed in Kafka 4.0. -
log.message.timestamp.difference.max.ms(service-level): Uselog.message.timestamp.before_max_msandlog.message.timestamp.after_max_msinstead. These settings define the acceptable timestamp range for messages.
Update your configurations before upgrading to avoid validation errors.
Transitioning to KRaft
With the release of Apache Kafka® 3.9, Aiven introduces support for Apache Kafka Raft (KRaft), the new consensus protocol for Kafka metadata management. KRaft simplifies the architecture while keeping compatibility with existing features and integrations, including Aiven for Apache Kafka Connect, Aiven for Apache Kafka MirrorMaker 2, and Aiven for Karapace.
Kafka 3.9 includes all features from Kafka 3.8. Some controller metrics are no longer available due to the transition to KRaft mode. For details, see Apache Kafka controller metrics. ACL permissions and governance behaviors remain unchanged.
For a detailed overview of how KRaft mode works and how it differs from ZooKeeper-based metadata management, see KRaft in Aiven for Apache Kafka®.
Availability and migration
New services
- All new Aiven for Apache Kafka services with Kafka 3.9 run KRaft as the default metadata management protocol.
- Startup-4 replaces Startup-2 plans in Kafka 3.9 and later. All feature restrictions from Startup-2 also apply to Startup-4, including Datadog restrictions.
- Available on all cloud providers.
Existing services
- Migration from ZooKeeper to KRaft is part of the upgrade from Apache Kafka 3.x to 3.9. This migration will be available soon.
- Aiven will notify you when your service becomes eligible for migration. For details, see Migration from ZooKeeper to KRaft.
- After migrating to Kafka 3.9 in KRaft mode, you can upgrade to Kafka 4.0 or later.
- Aiven has extended support for Apache Kafka 3.8 to give you more time to complete the migration. For the EOL date, see End of life for major versions.
Performance impact
Performance testing across different cloud providers and plan sizes has not shown significant changes.