Diskless topics architecture
Diskless topics extend the Apache Kafka® storage model by replacing local disk storage with cloud object storage. This approach reduces broker responsibilities and avoids inter-broker replication for diskless topics.
The architecture introduces an internal metadata service (the Batch Coordinator) and relies on object storage for durability and scalability.
How diskless topics work
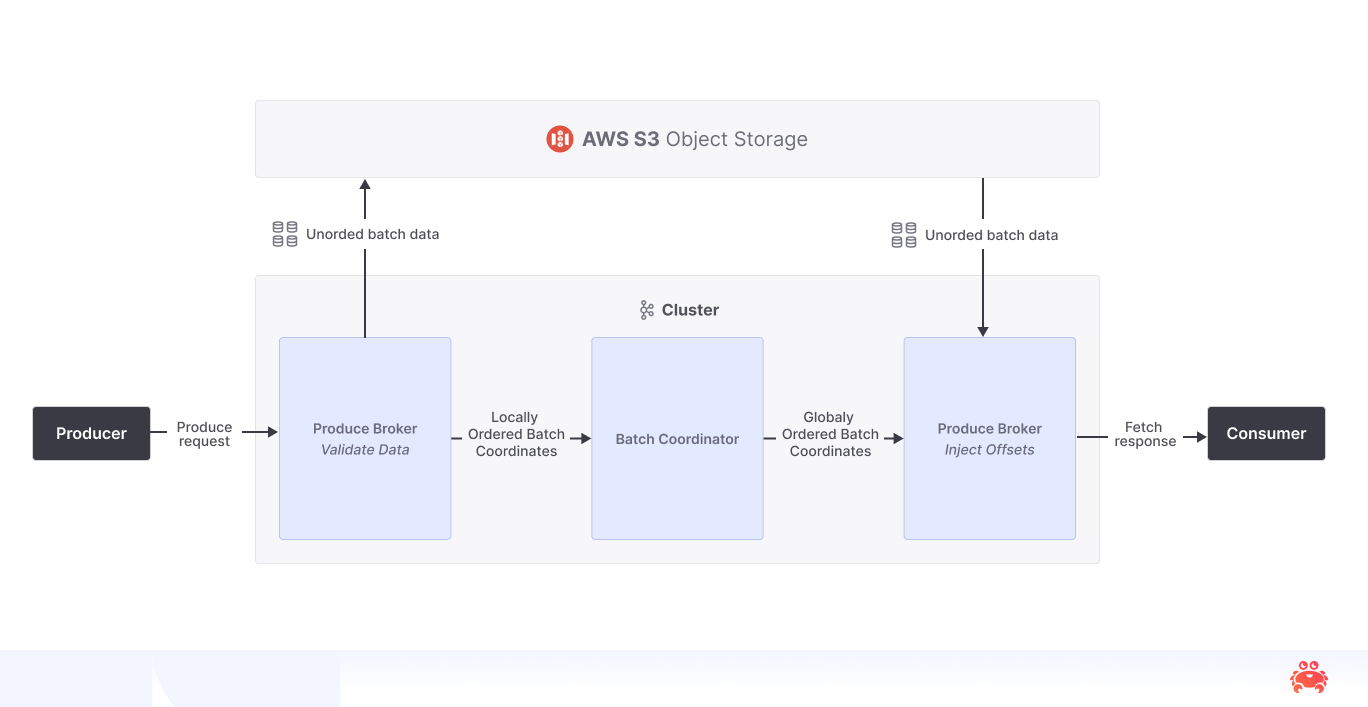
In diskless topics, brokers write messages in batches to object storage. Each batch is registered with the Batch Coordinator, which tracks its offset range and location. Consumers use this metadata to fetch message data directly from storage. Frequently accessed data may be cached on brokers to reduce latency.
Apache Kafka’s partition and topic model remains unchanged. Diskless topics continue to support parallelism and ordering guarantees, using object storage for the data path and the coordinator for metadata.
Leaderless data layer
In diskless topics, partitions do not have leaders. Any broker in the cluster can read data from any diskless topic partition because all brokers access the same underlying object storage. This design eliminates inter-broker replication for diskless topic data and reduces operational complexity.
Although the data path is leaderless, metadata still requires coordination. Diskless topics use the Batch Coordinator to manage this metadata. It tracks which data batches map to which offsets and where they are stored. To ensure consistency, the Batch Coordinator has a single leader that handles updates and preserves message order across the cluster.
To reduce costs and latency, brokers are designed to access object storage and serve cached data within the same availability zone (AZ). This AZ-aware affinity minimizes cross-zone traffic and improves performance, especially in cloud environments where network costs between zones can be high.
Role of object storage
For diskless topics, object storage replaces the local disk storage used in Classic Kafka services. Instead of writing log segments to disk, brokers batch messages and upload them to cloud object storage.
This design shifts durability and replication responsibilities from Kafka to the cloud provider, reducing broker-to-broker data transfer and operational complexity.
To improve performance, brokers cache recently read data. When a broker fetches an object, it temporarily stores the data to speed up future reads—especially within the same availability zone.
Batch Coordinator and metadata
The Batch Coordinator manages metadata for diskless topics. It assigns offsets to message batches, tracks where each batch is stored, and preserves message order within partitions. It does not handle message data directly.
When you schedule or start maintenance for an Aiven Inkless Kafka service that uses diskless topics, the internal Batch Coordinator is updated in the same maintenance window as the Kafka service. Maintenance details for both components are shown together in the service’s maintenance view in the Aiven Console.
Services with mixed topics: classic and diskless
Inkless Kafka services can include both classic and diskless topics in the same deployment:
- In Classic Kafka services, classic topics store data on local disks managed by brokers.
- In Inkless Kafka services, classic topics use managed remote storage.
- Diskless topics store data in cloud object storage.
- Metadata for both topic types is shared using Kafka’s KRaft protocol.
This setup supports gradual adoption. You can run classic and diskless topics side by side, depending on your use case. Some features, such as transactions, are supported only on classic Kafka topics.